算法分类
1. memory-based :
协同过滤 collaborative filtering
基于用户的协同过滤:
找到相似用户(计算用户相似度),再推荐别人喜欢而自己未接触过的。
用户A和用户B对相同物品集合有兴趣(阅读/点赞/购买),则A和B之间有一定的相似度。简单点的例子,用户A对物品{a, b, d}有过行为,用户B对物品{a, c}有过行为,利用余弦相似度公式计算A和B的相似度为:![image_1bvk4coj0mhrr3i91tngc1eovp.png-7.5kB]()
假设要对A做推荐,而B是相似度最高的用户,则可以向A推荐物品c。
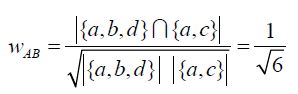
[^normalization]: 面向程序员的数据挖掘指南 https://wizardforcel.gitbooks.io/guide-to-data-mining/content/3.html
[^tag_based]: 《推荐系统时间》#4.3.2 P106 利用用户标签数据
[^ibm_rec_guide]: 探索推荐引擎内部的秘密 https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/index.html”>1 :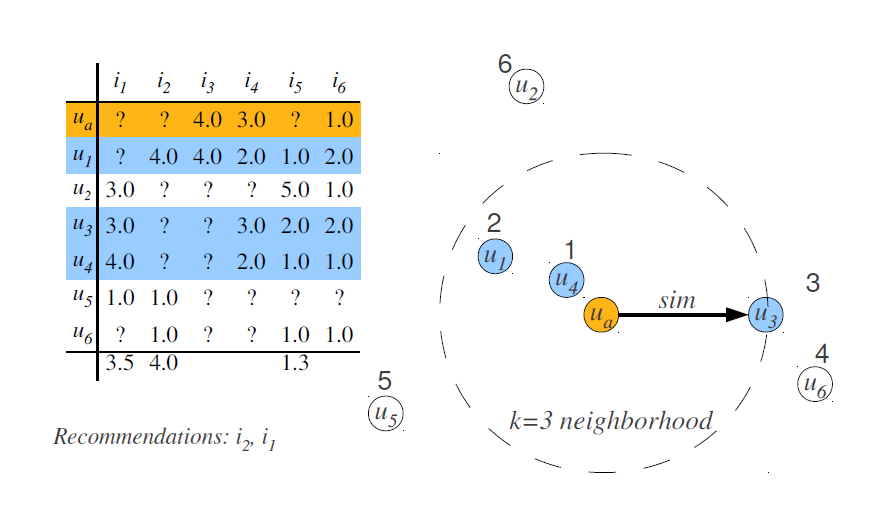
假设在已有左图用户-物品评分矩阵的情况下,对用户a做物品推荐。
首先通过一定算法,计算用户a与其他用户v的相似度S(a, v),选择前k个相似度最高的用户,则这些用户大多都喜欢的而目标用户a却没有做评价的物品,就是值得推荐的物品。怎么衡量“大多”呢:将相似度S(a, v)作为权重,乘上用户v对每个物品的评分序列,遍历k个用户,对加过权的评分求和,然后就得到比较可靠的用户a对物品的感兴趣程度,去掉用户已经评分过的物品,做次排序即可作为推荐列表。
上述的选择k个最相近用户做参考依据来推荐物品的过程,又被称为k近邻方法。
对于相似度的计算,通常有下面几种方法:
Pearson相似度
![pearson_sim]()
Cosine相似度
![cosine_sim]()
Jaccard 相似度
![jaccard_sim]()
Log-Likelihood Ratio
![log-likelihood]()
参考: https://tech.meituan.com/mt-recommend-practice.html相似度算法的选择没有定论,甚至于完全可以根据一些特征,设定自己的相似度方法。现在我使用的都是余弦相似度。
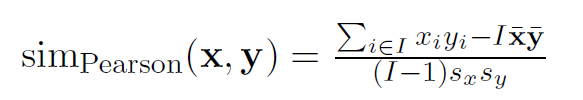
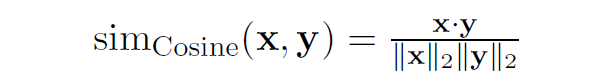
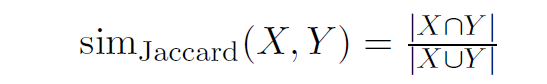
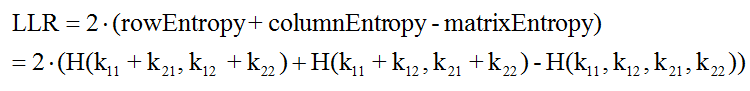
基于物品的协同过滤:
基于物品的协同过滤,思想与基于用户的协同过滤是一样的。
计算物品之间的相似度,然后根据物品的相似度和用户的历史行为给用户生成推荐列表。
这里的物品相似度使用了以下公式:
Wij = |N(i)∩N(j)| / sqrt(N(i)^2 * N(j)^2)
其中N(i)指喜欢物品i的用户数,N(i)∩N(j)指同时喜欢物品i和物品j的用户数。这里的物品相似度,是通过用户-物品关系矩阵算得的,而不是直接比较物品间的属性特征,这样能够更好地挖掘出物品隐性的联系,如“啤酒尿布”案例。
协同过滤是推荐系统里最基础也最常用的方法,推荐的结果有迹可循能够在UI上做出推荐原因的解释(如跟某某物品相似,某某用户也喜欢该物品),是绝大多数电商推荐系统的基础算法。
但缺点也很明显:
由于强依赖于用户-物品行为矩阵,当矩阵稀疏时,效果会比较差,
同理,当出现新物品/新用户时候,由于还没有在矩阵中建立起联系,无法通过简单的协同过滤算法给出推荐,这也就是常说的“冷启动”问题。对于冷启动问题,下文另有解释。
协同过滤还可以增加许多优化,例如考虑到用户兴趣会随时间变化,将时间信息纳入相似度的计算;还可以对过于热门的物品或行为过多的用户增加惩罚系数,避免被带偏;以及对评分矩阵作归一化<span class=”hint–top hint–error hint–medium hint–rounded hint–bounce” aria-label=”Recommender Systems From Content to Latent Factor Analysis, IDA SMU
[^normalization]: 面向程序员的数据挖掘指南 https://wizardforcel.gitbooks.io/guide-to-data-mining/content/3.html
[^tag_based]: 《推荐系统时间》#4.3.2 P106 利用用户标签数据
[^ibm_rec_guide]: 探索推荐引擎内部的秘密 https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/index.html”>1处理。
尝试过引入前两种优化,实现起来也并不难,这里就不细讲了,可以参考《推荐系统实践》的相关章节。
2. content-based :
提取物品特征,把用户的行为映射到物品特征
基于标签的推荐系统是典型content-based推荐系统。如果纯粹以标签为纽带,可以得到以下一种简单的算法<span class=”hint–top hint–error hint–medium hint–rounded hint–bounce” aria-label=”Recommender Systems From Content to Latent Factor Analysis, IDA SMU
[^normalization]: 面向程序员的数据挖掘指南 https://wizardforcel.gitbooks.io/guide-to-data-mining/content/3.html
[^tag_based]: 《推荐系统时间》#4.3.2 P106 利用用户标签数据
[^ibm_rec_guide]: 探索推荐引擎内部的秘密 https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/index.html”>1:
(1)统计每个用户最常用的标签。
(2)对于每个标签,统计被打过这个标签次数最多的物品。
(3)对于一个用户,首先找到他常用的标签,然后找到具有这些标签的最热门物品推荐给这
个用户。
[^normalization]: 面向程序员的数据挖掘指南 https://wizardforcel.gitbooks.io/guide-to-data-mining/content/3.html
[^tag_based]: 《推荐系统时间》#4.3.2 P106 利用用户标签数据
[^ibm_rec_guide]: 探索推荐引擎内部的秘密 https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/index.html”>1是将标签作为用户属性寻找物品间的相似性: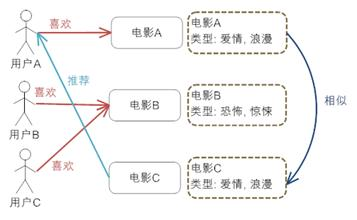
在我们现有的推荐系统里,使用了前者进行推荐。
由于当前数据集里标签信息相对较多,且含有大量LDA算法信息,标签质量较高,在几种算法里获得了相对更好的效果。
基于标签的数据集: hetrec2011-lastfm-2k
3. model-based
偏数学的方法,把推荐问题抽象为预测矩阵里未填值的问题,即预测评分问题。
电影推荐是典型的评分预测再做推荐的问题,如movieLens数据集,Netflix推荐系统比赛
如果没有直白的评分,则可以将用户的各种行为映射为评分,例如:
阅读 +1分, 点赞 +1分, 打标签 +1分, 收藏 +2分
将问题抽象为预测问题后,各种方法就非常多了,svd,svd++之类的矩阵分解方法是开胃菜,然后常见的机器学习方法,大多都可以套用算法试一下,线性回归、KNN、决策树、神经网络都可以应对此类问题,且都有不同程度的优劣,实际工程应用中以及比赛中,一般是将这些模型再套一层加权混合,在具体数据集里最终训练出合适的参数。由于这些算法对机器学习的基础知识要求较高,且做集成学习需要不少的工程经验,暂时没敢尝试,这里只实现了svd算法,效果也还算可以。
svd算法还是有些难以完全理解,不容易讲清楚,可以到以下链接看具体原理:
http://www.cnblogs.com/zrhai/p/5104928.html
在实际使用中,使用了Surprise库的SVD模型,直接train和predict即可,具体细节可以不关心。
推荐指标:
准确率 召回率 覆盖率 新颖度
排序准确度
评分准确度(RMSE MAE)
具体建议参考 《推荐系统评价指标综述》 电子科学大学学报 第41卷第2期
三大难点:
以下问题,是推荐系统业界都会碰到的问题,也是除推荐指标外,系统不断优化的方向
实时性:
推荐系统需要实时地更新推荐列表来满足用户新的行为变化,我们希望用户的每次行为,都能触发并计算出新的更好的推荐列表。
但由于推荐系统模型的计算量都相当庞大,不可能每次实时重新训练整个模型,只有少数算法如协同过滤支持增量计算(但计算量仍然较大),勉强能做实时。通常的做法是,整个推荐系统分多个部分,包括离线和在线的模型,离线的模型,一般隔较长时间计算一次,作为推荐的基础,而实时的模型,要支持流式计算,主要通过最近的用户行为特征修正推荐列表。参见Netflix推荐系统架构图:http://www.infoq.com/cn/news/2013/04/netflix-ml-architecture冷启动:
对于新用户,由于没有历史行为,无法与物品建立起联系,造成无法推荐。对于这种情况,不少应用会要求用户手动输入喜好,以及填充年龄、性别等信息,通过这些东西可以初步建立起用户画像,做一定程度的推荐。也可以借助社会关系或其他平台数据来获取用户特征,例如今日头条就会在用户注册时获取微博历史信息作为用户画像的一部分。
对于新物品,可以用数据挖掘的方法,先提取部分物品特征,基于content-based进行推荐,协同过滤强依赖于用户-物品关系矩阵,如果一个系统只实现了协同过滤而没有做content-based类型的推荐系统,那么新物品就没有机会被推荐到,可见,推荐系统的是很有必要做多种算法的集成的。
对这两种冷启动问题,也可以用热门物品/新物品列表暴力解决。数据太稀疏:
对数据集做聚类处理,例如将相似物品进行聚类,用户对物品的行为太稀疏,则将同一类内的物体做同样标注处理,用户没接触过的物品,但由于用户喜欢过这一类物品,也假定会喜欢它,从而构造出一个比较稠密的矩阵。这个只是个思路,具体效果需要实验一下。
其他推荐资料:
《推荐系统实践》项亮
IBM推荐系统系列文章
https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/index.html
面向程序员的数据挖掘指南
https://wizardforcel.gitbooks.io/guide-to-data-mining/content/2.html
推荐系统工程比赛(预测点击率):
https://www.kaggle.com/c/avazu-ctr-prediction
数据集:movieLens, hetrec2011-lastfm-2k,
KKBox’s Music Recommendation Challenge(Kaggle)
- 1.Recommender Systems From Content to Latent Factor Analysis, IDA SMU
[^normalization]: 面向程序员的数据挖掘指南 https://wizardforcel.gitbooks.io/guide-to-data-mining/content/3.html
[^tag_based]: 《推荐系统时间》#4.3.2 P106 利用用户标签数据
[^ibm_rec_guide]: 探索推荐引擎内部的秘密 https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/index.html ↩