原由:
1、用户自定义 SharkTime 功能已经基本做好,但该功能的交互是基于悬浮球操作,手动触发不够便利自然,因而考虑是否能够增加唤醒词触发,这样交互方式更加自然有趣,玩法多样。
2、之前在 I19tService 中已有基于DNN的音频识别功能(听声辩位,识别枪声),已有音频处理的基本技术储备,但是识别率不高,效能较差。
语音识别基础介绍
语音识别,ASR(Automatic Speech Recognition)
文中会出现很多专业词汇,其实我也只是把他们堆砌在这里,大致知道用来干什么的,原理却不熟悉。
音频信号
原始音频信号如下图[1]: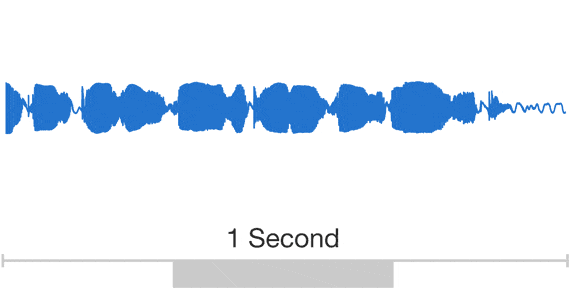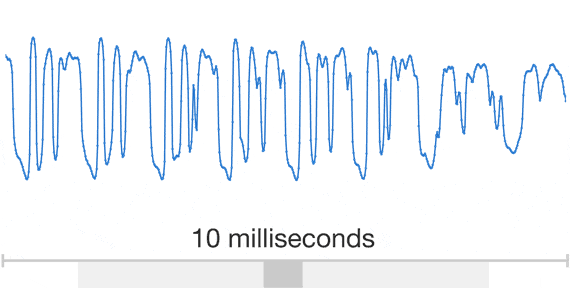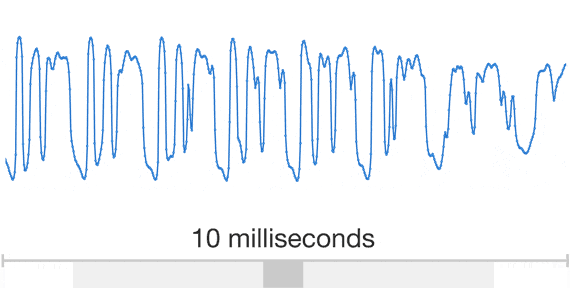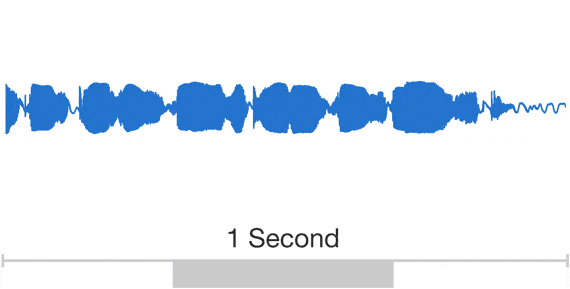
可以看到,音频信号的信号量实际上是非常大的,直接拿原始数据pcm去做分析,极不划算。
信号中更有价值的是频域信号,为此,音频信号的分析,首先要做时域到频域的转换,也就是傅里叶变换。
频谱特征
傅里叶变换的原理及应用的讲解可以看李永乐的视频。
通过在一小段时间上的音频信号,做傅里叶变换,我们能够得到类似下面的频谱图[2]: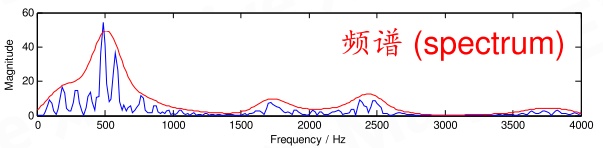
将一整段音频做分帧(每20~50ms取一小段,两帧间还要有窗口交叠(帧移),再对每帧加窗函数如汉明窗以平滑信号(加窗))操作,对每一帧做傅里叶变换,可以得到如下频谱图:
如果是进行语音识别,通常在频谱之后,会再经过一组Mel滤波器得到mel频谱,然后再进行倒频谱操作(取对数再逆傅里叶变换),最终得到梅尔频率倒谱系数,简称MFCC。
具体原理可以参考这里,总结来说,就是Mel滤波器根据人耳听觉系统的特性对数据做了一轮变换,而倒谱变换用于进一步提取频谱特征,如共振峰等。所以对于语音识别类问题,一般MFCC特征提取就是系统的第一步了。而如果是处理与人耳听觉无关的音频的话,可以只用频谱图做特征。
MFCC整个算法还是很复杂的,好在这个东西已经相当成熟,基本上语音相关的工具包里都已经实现好了,都是输入pcm就好,甚至分帧的参数都不用考虑太多,在下面具体实践的时候可以感受到。Tensorflow 中可以通过以下方式进行mfcc特征提取:
- 按照API说明文档,按序依次进行每一步的转换操作(stft->mel->log->mfcc)。
- 借鉴TensorflowTutorial - AudioRecognition项目的预处理代码,直接使用contrib包里的mfcc方法。
OK,无论是普通的频谱图还是MFCC,我们已经将原始 PCM 数据转为一组按时序排列的特征向量,接下来正式使用模型进行识别。
我这里将识别方法简单分为传统方法和end-to-end方法。
End-to-End 方法
我们前面已经得到了频谱图,既然是图,那么一个很简单的想法就是直接按照图像分类的套路,把频谱图经过几层卷积来做个分类。这种想法确实是可行的,实际上我们听声辩位中对枪声、车声等的识别分类,就是采用这种简单粗暴的方法。Google有一篇论文专门讲了这种方法《Convolutional Neural Networks for Small-footprint Keyword Spotting》,我们姑且叫他 DeepKWS 方法,这类架构可大致用下图表示:

左侧是前面提到的特征提取过程,使用一个滑窗,每次将固定长的特征送入模型作计算;
中间是几个卷积block再接softmax做分类,一般两三层卷积就够用,输出的结果中,filler类别指代非目标类别,如背景音,其他的是关键词类别;
右边是输出的结果,每次识别得到一个类别结果,随着滑窗推进形成一个序列。
从上图我们可以看出,虽然左边 “answer”、“call” 分别只出现了一次,但在右边序列图里,每个关键词都被连续激活很多次。这意味这种简单架构不能准确表征每个词出现了几次,它只适合于在一个时间点判断是否有某个关键词出现。由于得到的结果不能拼成句子,因此DeepKWS还不能直接做语音识别,后面其实还要接传统的语言模型、NLP等才能完成复杂功能。当然,这种架构对于一些简单的命令动作已经完全足够了,比如说“开灯”、“关灯”,就是要注意后续逻辑要处理好,避免重复触发。
(Hidden Content)
DeepKWS作为一个语音识别的端到端模型还不够格,因为它只能得到关键词的序列,一个端到端语音识别模型还要能做到直接输出一段准确匹配的文字。
假设从已有的 DeepKWS 架构扩展开去,那就需要能够直接处理一段音频序列,以及把原来 DeepKWS 右侧的序列结果中重复的部分给删掉,如此一来,输入输出都会变为不定长且不匹配。
由于整个输入变为不定长序列,所以一般用 RNN 的结构整个包起来。
而针对输入输出难以对齐的问题,我们引入 CTC loss 来驱动训练过程。
由于 CTC 相关的模型我也没有实际尝试训练过,本身算法也较复杂,这里就不细讲了,以免混淆视听,推荐两篇文章,distill和blog
百度的 DeepSpeech 就是一个典型的端到端的语音识别框架:
$h_t^{(1)}$、$h_t^{(2)}$、$h_t^{(3)}$ 为三个全连接层,$h_t^{(f)}$ 和 $h_t^{(b)}$ 组成双向LSTM,再接全连接层和softmax后,使用CTC进行训练。
在实际应用模型进行推演的时候,还要增加解码的过程,解码的过程就是在得到softmax各个 “word” 的输出概率后,结合语言规律和当前上下文,寻找可能性最高的一句话。我们在使用输入法或语音助手的语音识别功能的时候,往往会看到最后有个字不断跳动,在说一段话时,识别出新单词的同时前面的字也可能变化,这个就是解码过程的体现,解码器在不断寻找更合乎常理的一段话。
解码过程更偏向于NLP领域,DeepSpeech 这里使用的是 ngram 模型[4],关于语言模型,下面还会继续涉及。
端到端的方法因为主体部分都是深度神经网络,近些年发展得很快,在数据充足的基础下,效果已经明显超过了传统方法,很多大厂已经将这类方法作为主要的语音识别手段。
这里举例的 DeepSpeech 已经发展到了第三代,而其他不同结构的端到端模型也是数不胜数,训练方法其实并不局限于CTC,据说也可以直接用seq2seq的思路,频谱特征提取也可能不再是必须,wavenet就已经直接把pcm作为输入。但就我目前所了解到的,它们似乎都还没能摆脱掉语言模型,也就是说,端到端如今仍是个相对的概念。
语音识别技术还在日新月异,或许未来终将会有更优美的模型来实现真正的端到端。
端到端的语音识别方法准确率很漂亮,但对于我们来讲,也有几个明显的问题:
- 模型庞大、训练耗时。虽然层数看起来不是特别多,但是RNN、时序问题训练起来要难得多,模型也难以裁剪。
- 训练需要大量语料。往往需要几十个小时以上的音频语料,如果要适配特殊需求,语料的收集整理会更麻烦。
- 语言模型庞大。DeepSpeech 的klm文件居然有2个G,而 pocketsphinx 中文语言模型只有60m。
现有的端到端方法也不是一蹴而就的,而是从传统方法的思路出发,把一个个模块替换成了新的方法,前文中提到的语言模型就是传统方法的一个步骤。因此,尽管现在端到端方法效果已经很好,传统方法社区依然活跃着,而每个搞语音相关的都必须先把传统方法的基础打好。
接下来我们简单看下传统语音识别方法的各个步骤,最后以PocketSphinx为例尝试做一个唤醒词方案。
传统方法
所谓传统方法是指从 90 年代以来逐渐成熟的一套基于统计学的语音识别方法,包括以下步骤:
特征提取(feature extration)->声学模型(acoustic model)->发音词典(lexicon)->语言模型(language model)
在此之前,语音识别还是用专家系统的思路,效果完全不行,而这种方法本质上是一套统计学方法,最早是由李开复等人在读博士[5]时提出并开发的,项目叫做 Sphinx。
首先要了解以下概念:
音素(Phoneme):经常被简称 phone,是指发音最小的单位。英语国际音标共有48个音素,而CMUdict[6]使用了39个音素。
音节(Syllable):完整发音的单位。以中文来说,一个字对应一个音节;以英文来说,一个单词会对应到多个音节,例如“tomorrow”对应三个音节。
单词(Word):如英文中的 “word” 就是一个单词。中文中一般每个字都是一个 word,而有另外有多个字可以组成一个 word,例如 “单词”、“单”、“词”是三个单词。
特征提取
跟上面端到端方法中的特征提取是一样的,不再赘述。
声学模型
从特征向量计算得到音素,一般采用 GMM-HMM 方法。
GMM(Gaussian Mixture Model)用来将声学特征进行一次聚类,使用多个高斯分布的拟合来表征声学似然度(acoustic likelihood),GMM会将一帧声学特征计算得到状态观测概率(observation likelihoods),可以粗略理解为GMM用来猜测大概会是哪类音素。GMM 是要对声学特征做一次聚类,聚类的话,就有很多替代方法,比如在GMM之前似乎是使用VQ(vector quantization)的,而在神经网络成熟后,现在GMM基本已经都替换成DNN了。
HMM(Hidden Markov Model, 隐马尔科夫模型)用来建立声学特征的变化序列与音素甚至整个语言模型的网络关系,这个输入的序列信息就是GMM在每一帧上的结果,一个经典的 GMM-HMM 框架图如下图所示:
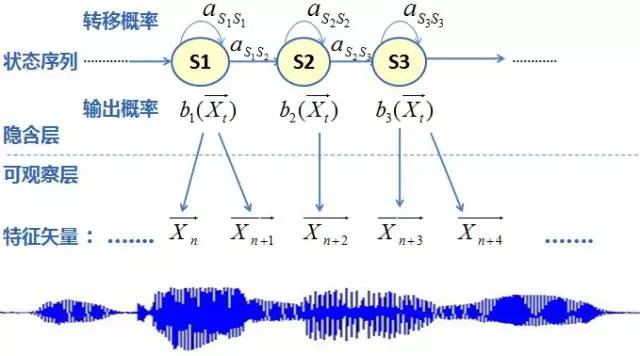
HMM 是在马尔可夫链的基础上,再加一层假设。原来的状态不直接可见,但可以由其他可见的状态来体现,而原来的马尔可夫链是指满足马尔可夫假设的状态链模型,这个假设就是下一状态的概率分布只能由当前状态决定,与再往前的状态无关。HMM 的具体内容建议再参考别处,一般的统计学或机器学习的教材里应该都有,或者从这个知乎问题的讨论里也可见一斑。
HMM 不仅是传统声学模型的核心,也是整套传统方法的关键和难点,我花了好长好长时间才大致搞明白 HMM 具体在ASR系统里都是怎么算的。
总之,我们需要知道,建立好的 HMM 模型将是一个巨大概率网络,在 ASR 推演时,使用 Viterbi 方法计算找到一条概率最大的路径,那条路径就是最符合的识别结果。到此为止,识别的结果还只是音素,而如果整个网络通过下面要讲的词典和语言模型继续扩充,最后搜索的结果将是整句话的识别结果。
发音词典
发音词典用来建立起音素和单词的关系,PocketSphinx 里的字典数据如下图,每行第一个空格前是单词,后面是对应音素序列。
中文:
英文:
语言模型
语言模型是用来计算一个句子出现的概率模型,通过限制输出序列,减少搜索空间,提高效率。对训练文本库进行语法、语义分析,经过基于统计模型训练得到语言模型。
最常用的语言模型是 n-gram ,包含单词序列的统计数据和有限状态语言模型。
将上面几个步骤连接起来,整个流程可用下图表示: [7]
[7]
这样传统语音识别的几个步骤和他们的概念就基本讲完了,由于我们最开始也只准备训练一个唤醒词模型,而对准确率要求还没有特别高,因此实际上很多语料准备、声学语言模型的训练并不需要自己去做,我们即使作为语音识别的外行,也可以借助几个工具快速实现和移植一个唤醒词模型。
接下来讲一下使用 PocketSphinx 生成 “小鲨同学” 唤醒词并在Android端运行的一次实战经验。
PocketSphinx 实战
现在主流的传统方法ASR引擎有 HTK、sphinx、kaldi,HTK 有些太老了,kaldi感觉用起来需要训练的步骤很多,很麻烦。
使用 pocketsphinx 训练唤醒词的具体步骤主要启发自这篇文章:中文对话机器人开源项目基于 PocketSphinx离线引擎的语音唤醒优化
PocketSphinx 有一整套很好的官方教程文档: https://cmusphinx.github.io/wiki/tutorial/
前置准备:
我们主要关心 android端的方案,首先把整个 pocketsphinx-android-demo 下载或clone下来,将这个demo运行在手机上,可以先尝试一下唤醒词 “oh mighty computer” 以及后面的 ASR 流程。
步骤如下:
1. 确定唤醒词。
唤醒词其实可以同时设定多个的,我们这里设定“小鲨同学”、“小鲨录屏”。要注意自定义的唤醒词在声学特征上应尽可能明显易识别
唤醒词的音节覆盖尽量多,一般4个音节,也就是三、四个字,相邻音节尽可能规避,字要发音清晰响度大。
2. 使用 lmtool 生成词典和语言模型。
准备语料,并使用 lmtool 转换成词典和语言模型。
为了模型不被 与目标唤醒词相似的声音 误触发,我们可以增加一些干扰词提高准确率。例如 “小萨”、“香山” 与 “小鲨” 相似,我们把它们加进去(当然“小莎”不能加进去),汇集成的关键词语料如下方左图。
把这个文件上传到 lmtool 中,编译并下载生成的资源包。得到的文件中,.lm 和 .dic 最为重要,分别对应 语言模型ngram 和 词典。.lm文件内容类似下方右图,.dic里只有分词好的单词,还没有与音素建立联系,下一步就是把这个发音词典改好。
| 关键词 | .lm文件 |
|---|---|
 |
 |
3. 修改声学模型以及词典。
pocketsphinx 的 android demo 中默认的声学模型为 “cmudict-en-us”,我们由于都是中文唤醒词,建议改用中文声学模型,中文声学模型包括有声调和无声调两种,我这里使用的是中文有声调的资源包,下载地址。
直接使用 “cmudict-en-us” 也不是不可以,因为这个模型本身已经自带了一些中文词汇,例如词典里可以找到如下图的部分,这些明显都是中文词汇:
不过这个词典还是有很多中文字词没有收录,如“中”,好多词找起来也很麻烦。应该是有同时支持中英文的模型的,但我在sourceforge里没找到。
另外使用这类包括外文的声学模型时,前面 lmtool 转换的中文词也要记得对应换成拼音。

下载好的文件解压后,zh_cn.cd_cont_5000 目录里都是声学模型相关文件,将整个文件夹放到项目 assets/sync 目录中。然后还剩zh_cn.dic和zh_cn.lm.bin两个文件,看名字也知道,分别是词典和语言模型,如果直接配置使用这两个文件,那项目就已经实现了一个离线的中文语音识别系统,而我们这里要把识别目标变为特定的唤醒词,所以这两个文件就不直接用了,而是要替换为前面一步得到的模型文件。
将上一步的从lmtool网站下载得到的 .dic 文件做以下处理:
从zh_cn.dic词典中找到每个目标词的对应音素表示方法,补充到 .dic 文件中每个词的后面。改完后变成类似下面这样:
在韵母后的数字表示声调。中文词后面有括号表示多音词。
通过这种方式,建立好了我们的自定义词汇和原有声学模型音素间的映射关系。
到目前为止,完成 ASR 引擎所需的声学模型、发音词典、语言模型都准备好了,让我们来使用 PocketSphinx 的 android demo 测试一下。
4. 移植到手机测试。
将准备好的 .dic 和 .lm 文件拷贝到项目 assets/sync 文件夹中,项目代码中,SpeechRecognizer的启动代码做类似下面的修改。
1 | recognizer = defaultSetup() |
把其他无关的 search 项目注释掉,然后在手机上运行,应该就可以识别到目标词汇了。继续增加逻辑,如果最后识别的词汇能够拼成目标关键字“小鲨同学”和“小鲨录屏”,就认为唤醒了一次。
经实际测试,我现有的这个模型,如果在嘈杂的环境里(办公室),“录” 和 “屏” 这两个字误识别的概率特别大,而且 recognizer 必须每过 一段时间后重启一下,否则会报类似以下错误,而此时识别引擎实际已经宕住了。
1 | W/cmusphinx: WARN: "ngram_search.c", line 396: Word '屏' survived for 44080 frames, potential overpruning |
另外在一开始使用中文模型的时候,还报过以下问题:
这里的意思是说,由于 中文 phones 数目比英文多,运行时数值越界,需要将源代码中相关参数增大并重编译出 aar。
参考官方教程配置好各依赖项并成功编译,把
pocketsphinx-5prealpha\src\libpocketsphinx\fsg_lextree.c文件中的FSG_PNODE_CTXT_BVSZ参数从 4 改到 8。再重新 gradle build,把 buid/outputs/下的 aar 文件作为依赖导入到原 pocketsphinx-android-demo 中。
在嘈杂和安静的环境下测试该模型的 Demo 效果如下图:
| 嘈杂 | 安静 |
|---|---|
 |
 |
随后我们将该模型移植到 I19tService 项目中,然后碰到了个相当尴尬的问题:
在游戏之外的应用中,识别以及后续功能效果都还可以,而一旦在游戏中,识别效果急剧下降。经调试发现,在轻型应用中,识别正常,麦克风音频数据正常,而在重型应用中,麦克风音频数据就会变得断断续续。一开始还猜测是因为游戏设置造成有线程抢占问题,后来比较了开关pocketsphinx功能前后的CPU占用率才意识到,这个ASR模块在运行时算力消耗太大,在重型应用中,量变引起质变,进而引发线程抢占问题,麦克风buffer丢掉很多数据。
由于性能问题,pocketsphinx 的方案只好被抛弃,不过使用 PocketSphinx 的过程确实很好地帮助我了解了传统语音识别方法的整体流程。
后来i19t上最终使用了百度ASR的唤醒词方案:
功耗还可以,约30~40ma,准确率很高,各方面易用性强,更关键的是离线唤醒词完全免费。
如果有自定义唤醒词的方案需求,建议考虑百度ASR或snowboy,两者特性如下:
百度ASR:功能强大全面,包含在线、离线各种功能,其中离线唤醒词完全免费。
唤醒词通过在官网输入关键字直接生成,可自定义三个唤醒词,可使用百度预设的唤醒词如“播放”、“停止”等,最多十个唤醒词。
sdk依赖包最小可以不到1M(仅使用唤醒词能力)。Snowboy: 仅有唤醒词功能,对个人使用免费。在官网或通过api上传三段同一唤醒词的音频文件,随后生成模型文件。sdk依赖包约2M。
SDK比百度ASR较开放,有VAD结果,阈值可调,使用起来更灵活。
但是生成的模型自己用还可以,一换人就识别不出来了,我猜测模型是通过类似transfer-learning的手段生成的。
后话:
(Hidden Content)
在语音识别体系中,有很多是完全为了解决语音识别中的具体问题而建立的模型/算法,诸多从统计学假设思路出发的算法,与其他领域有很大不同。尤其对机器学习的理论基础要求很高。 从网上查找入门资料的时候,发现绝大多数文章都只是把术语、流程和定义罗列一遍,很是摸不着头脑,本文写完发现也只落得相似境地。才疏学浅,太多东西完全不懂,实在不敢下笔。读者若真有搞ASR的需求,建议还是不要盲人摸象了,找本教材再认真研读下吧。 除教材外,在网上发现有以下高校课程或资源很值得推荐:MIT ASR
Columbia Julia CS6998-2019
HTK Book(网上推荐,太长未看)
- 1.WaveNet raw audio https://deepmind.com/blog/wavenet-generative-model-raw-audio/ ↩
- 2.知乎-语音信号处理中怎么理解分帧?https://www.zhihu.com/question/52093104/answer/225983811 ↩
- 3.Seppo Fagerlund. 2007. Bird species recognition using support vector machines. EURASIP J. Adv. Signal Process 2007, 1 (January 2007), 64-64. DOI: https://doi.org/10.1155/2007/38637 ↩
- 4.自然语言处理中N-Gram模型介绍 https://zhuanlan.zhihu.com/p/32829048 ↩
- 5.KF Lee. Automatic speech recognition: the development of the SPHINX system. Springer Science & Business Media ↩
- 6.CMUdict: http://www.speech.cs.cmu.edu/cgi-bin/cmudict ↩
- 7.图源:https://stevenocean.github.io/2019/05/02/first-meet-asr-and-kaldi-install-use.html ↩